Сообщение от h1dd3n
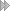
SELECT * FROM some_table
будет в 10 раз быстрее чем
SELECT * FROM some_table WHERE id IN [1, 5, 7]
??
херню понаписал как всегда.
|
Че? Два разных запроса полностью..
Я сравниваю:
SELECT * FROM some_table WHERE id IN [1, 5, 7]
И
SELECT * FROM some_table WHERE id = 1
В данном запросе, тут прямой hit по индексу.
А если поле не проиндексировано и не уникально, и у тебя 100 записей.
То будет O(a*b) либо O(a + b). В зависимости как реализован поиск, с или без временного индекса.
Сообщение от h1dd3n
Во-первых, вот это - либо вообще O(a*b) объясни своими словами,
Во-вторых, какие еще временные индексы ? По твоему мнению по каким данным база должна построить "временный индекс" ?? Приведи пример запроса (с IN, разумеется) в котором использование этого самого "временного индекса" даст преимущество.
IN на 1000 или на 2000 вообще не проблема.
|
Ты писал хоть раз простые функции поиска руками по своим данным?
Попробуй создай array и map данных, и напиши мелкий поиск по ним с IN функционалом на предпочитаемом языке. И посмотри на проблемы и скорости.