Сообщение от pax
Это какие такие дублирования данных? Можно же id записей одной коллекции хранить в полях другой. Запросы реляционные не сделать это да, но а часто это не нужно. Получил список сообщений, получи для них пользователей отдельным запросом.
|
Можно то можно, но в чём тогде смысл документарной базы данных, если мы из неё делаем реляционную (не избыточную и целостную), просто на "программном" уровне (в коде приложения), а не на аппаратном (в архитектуре самой СУБД). Причём вот такой запрос в той же MySQL
SELECT a.id,
a.name
FROM chat AS a
LEFT JOIN chat_users AS b ON b.chat_id = a.id
WHERE b.user_id = 1
(поля chat - id, name;
поля chat_users - id, chat_id, user_id)
Отработает горррраздо быстрее и проще, чем я сначала отдельным запросом запрошу документ пользователя с user_id = 1, а вторым запросом я вытащу документ чата, в котором найду "чаты" данного пользователя.
Я почему то твёрдо уверен что документарная структура мне не очень хорошо подходит.
Вот картинка (с хабра, не моя), описывает банальную ситуацию с лайками и коментами (я конечно не делаю лайки, но ситуация схожа):
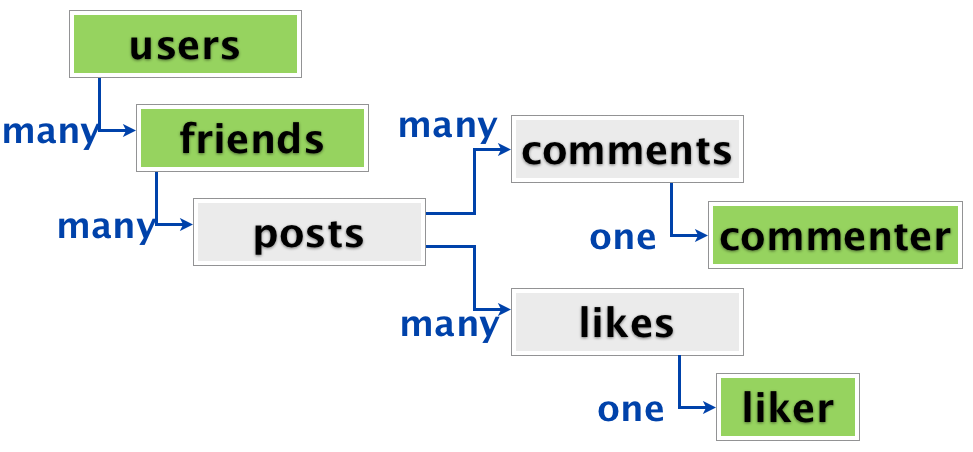
То что выделено зелёным - имеет один и тот же тип данных (то есть users). То есть, что бы достать инфу о всех лайках и комментариях у пользователя, надо:
- или хранить полностью всю инфу о самих комментерах и лайкерах следуя парадигме документарной СУБД, что бы все данные вытаскивать одним документом (дублирование (читай денормализация, избыточность данных) данных + чревато если лайкер/комментер, например, сменил какие то свои данные, например имя);
- или хранить ключи (id) на самих комментеров и лайкеров, но тогда придётся писать свой собственный "программный" JOIN, что является лишним гемороем и убивает основную фичу документарной СУБД - скорость за счёт доставания инфы одним документом (то есть попытку приведения документарной СУБД к недореляционной).
Цитата с хабра (перевод статьи про Диаспору), как раз именно так я и понимаю использование MongoDB для моей задачи:

Примерно так выглядит плотностью денормализованная лента активности.

Все копии пользовательских данных встроены в документ. Это лента Джо, и у него есть копии пользовательских данных, в том числе его имя и URL, на верхнем уровне. Его лента, содержит пост Джейн. Джо лайкнул пост Джейн, так что в лаках к сообщению Джейн, сохранена отдельная копия данных Джо.
....
Существует другой подход к решению проблемы в MongoDB, который будет знаком тем, кто имеет опыт работы с реляционными СУБД. Вместо дублирования данных вы можем сохранять ссылки на на пользователей в ленте активности.
При этом подходе вместо встраивания данных там, где они нужны, вы даете каждому пользователю ID. После этого вместо встраивания данных пользователя вы сохраняете только ссылки на пользователей. На картинке ID выделены зеленым:

(MongoDB фактически использует идентификаторы BSON — строки, похожие на GUID. На картинке числа, чтобы легче было читать.)
Это исключает нашу проблему дублирования. При изменении данных пользователей, есть только один документ, который нужно изменить. Тем не менее, мы создали новую проблему для себя. Потому что мы больше не можем построить ленту активности из одного документа. Это менее эффективное и более сложное решение. Построение ленты активности в настоящее время требует, чтобы мы 1) получить документ ленты активности, а затем 2) получили все документы пользователей, чтобы заполнить имена и аватары.
|
Ну, то есть, на реляционной СУБД конкретно такая задача не проблема вообще (заводим несколько таблиц и джоинами вытаскиваем нужные данные). Мой личный вывод по MongoDB - крутая хранилка не связанных друг с другом JSON-данных (аля медиатека). Если данные в двух разных хранилищах связаны какими то ключами друг с другом - значит мы используем MongoDB как реляционную СУБД, то есть не по назначению. Вот так я понимаю работу с MongoDB.
зыЖ Я ни в коем случае не говорю что MongoDB это плохо (во первых, - я с ней знаком всего 2 дня, во вторых - да кто я такой, что бы это говорить) и скорее всего не понимаю всех плюсов документарной СУБД и буду рад если мне кто нибудь примерно зарисует/распишет как надо правильно им пользоваться в моём направлении. Полную структуру что должно храниться и в какие моменты извлекаться могу расписать.
На любой SQL-СУБД реализую всё что мне надо довольно просто и быстро, с сохранением целостности и нормализации данных в случае какого либо изменения этих данных, чего абсолютно не гарантирует денормализованная структура (а если делать нормализованную структуру - то смысл в MongoDB для этой задачи отпадает).